
前言
我覺得這件事對我及 AngelFlame 來說很有意義,所以我覺得有必要花一點時間記錄下來這幾個月無聊時候所做的事情,沒錯這件事情就是一個很簡單卻也不簡單的 iOS app – HackerReader,從 Commit Log 看起來,整個小專案是從 2013 年 11 月開始,而第一版則是在 2014 年 2 月初上架,中間發生太多好玩又心酸的事情值得分享了,故事,就待我娓娓道來吧。
我不是 iOS developer 也沒寫過什麼 app,但因為是 Apple 愛用者手上有 Macbook pro 又有 iPhone,在心中的角落總是有一個想法希望未來某日能夠自己親自做個什麼簡單的 app 給自己及大家用。而說巧不巧,之前就和大學好友阿棋 (popochess) 及 小祐 (eyesbad) 組了個微型(男)團隊 – AngelFlame 能夠在大家下班、放假休息的時候一起來做點什麼,又剛好因為阿棋本來就是 iOS developer ,所以我們就把主題定在 app 這個領域上面,大家一起來激盪一下看能寫出什麼 app 吧!
因為我本身就有在看科技文章的習慣,所以我就把目標設定在一個 RSS Reader 的 iOS 載體,而考慮到主題及想要驗証「使用者付費」這個習慣在 iOS 平台上的普及度,我最後就選定了這個題目 – 「Hacker News only 的 RSS Reader」,也就是你看到的 HackerReader (後稱 HR)。
目標
因為 AngelFlame 是很隨性的一個團隊,主要就是一個人選定題目然後開工,主要的開發就都會是那個人(劍士主力角)為主,而阿棋因為有比較多相關的工作經驗,所以就是到處幫忙的角色(技師補血角),其他的時候就是大家互相提供 feedback ,覺得什麼不錯就加進來什麼不好就拿掉,因為時間、資源有限的關係,我們只先做最重要的功能,其他的就通通丟到 issue tracker 等到 1.0 版之後再說,而以 HR 這個 app 來說,我們要實作的有下面幾點:
- TableView based – 因為是提供文章的資訊型 app ,所以希望能夠很直覺的把文章呈現出來。
- Like – 很多時候我們都會看到很多好文章,所以希望能夠有 Like 這個功能來收藏它們留著以後看。
- Hints – 因為 Hacker News 上面的文章可以讓人投票來決定排名,也有評論的數目,所以我們希望能夠同時呈現這個資訊讓使用者知道哪個文章是重要的。
沒錯就這麼簡單,我們心中最基本的 iOS app 至少要有這三個功能,而這個也是我們 1.0 版最重要的目標,定好目標後就開工啦!
開發筆記
其實在寫這個 app 的時候沒有遇到什麼太大的問題(因為不是一個很複雜的 app ),但是還是有碰到一件很棘手的事情,那就是「資料來源」。因為我想要拿 hints (就是上面提到的評論數及投票數),而官方的 RSS feed 並沒有放出這個資訊,所以勢必就是要自己想辦法來拿到它。
而一開始我的想法就是透過 Yahoo Pipe 來 parse 整個 Hacker News 的頁面,然後再透過 XPath 去取出我要的 hints,這個做法一直可行也有用,因為從以前我都懶得架一個 Server 來 parse,成本很高也沒有必要,所以我都是透過 Yahoo Pipe 放出 JSON 來讓載體抓,然後分析出我想要的資訊再呈現出來,但是這次我踢到鐵板了 … 因為透過 Yahoo Pipe 拿資訊這件事情變得很不穩定,一開始我不知道為什麼偶爾會拿不到資料,我單純的以為只是小問題不用太 care,但是到最後 app 都快做完了,這個問題卻變的非常容易發生,幾乎最後都一直拿不到資料甚至是讓 app crash,去查了之後才發現 Yahoo Pipe 的那個 link 被 Hacker News Ban 掉了,所以才會有這個問題,但是卻時好時壞,所以我猜測是因為 Yahoo Pipe 可能會用不同的 Server (ip)來抓資料,如果那個 ip 的抓取量超過一個限制就會被 Ban 了 … 我之前天真的以為是 Hacker News 的問題,最後才發現是它的網路空間服務商 Cloud Flare 搞的鬼 !!
What the fuck is ScrapeShield !!!!
真的是他 X 的一山還有一山高,怎麼會有人寫出這一套這麼強大的系統來偵測客戶網站是不是正遭受 Scrapper 的攻擊愛護呢!他文章講到的一堆有的沒的真的是太潮了,就算看懂了也不知道他怎麼偵測的,所以也沒有辦法了解要怎麼突破這麼限制,這該怎麼辦呢!? app 都已經做到最後了總不能就因為這個該死的原因放手吧,身為 Engineer 就是要解決問題呀!所以我決定去諮詢昔日戰友 – Bu 的意見。
聊了一下我們覺得最保險的方法就是要自己 host 一個 backend server,因為這樣我們才有辦法自己掌握整個 app 及資料的狀況,很好,那我們就來架 server 吧!
後端架構
第一版的架構如下
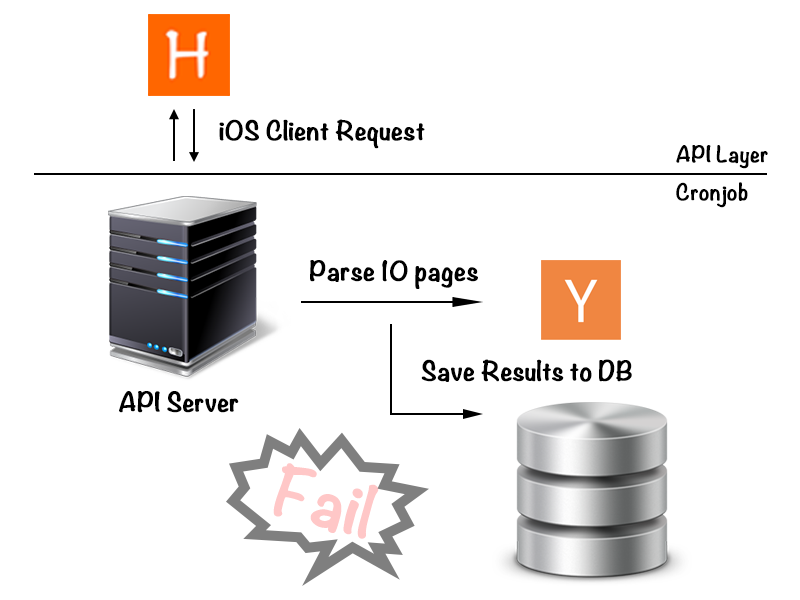
我們原本的想法很簡單,就是一個簡易的 API server 充當 Fetcher + Parser 的角色,每 30 分鐘就去執行一次爬行的動作,然後每次爬 10 頁的資料。但很不幸的失敗了,該死的 Shield 還是成功的把我們抓出來了,第一次作戰失敗之後我們有檢討了一下失敗的原因可能有以下幾點:
- 沒設 User Agent,所以試為 Bot
- 每抓一頁沒有設定間隔,抓太快所以被試為 Bot
很好,山不轉路轉,我們因此試了第二個版本:
第二版的架構如下
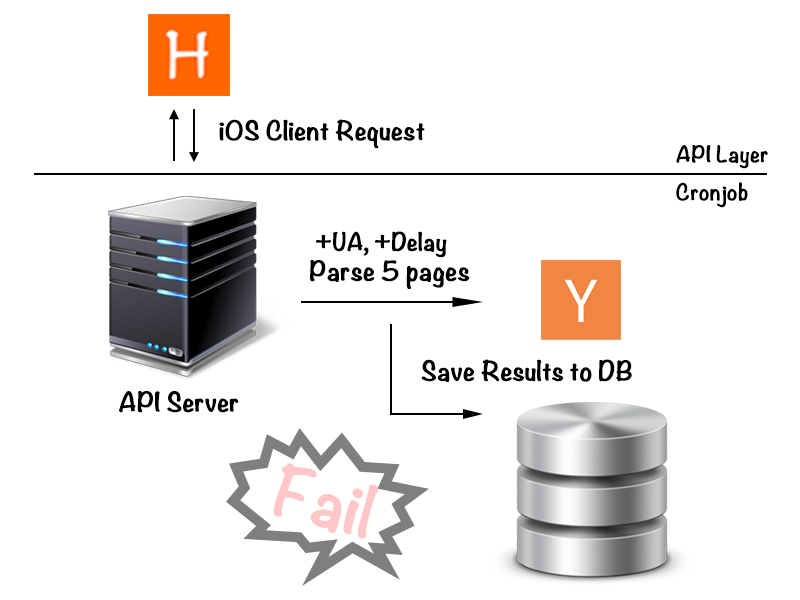
沒錯 … 我們還是失敗了,我們天真的以為只要加上 UA 還有 Delay 就可以解決這個問題,不得不說我們原本想說要騙就騙的真一點,連 delay 都還會多加上一個 random sub-delay ,試著逃過他們的偵測,不過最後還是告吹了 xD ,那到底該怎麼辦呢 … 該不會就要結束在這個地方了吧!?總明如髮如雪的我們當然不會就這樣放棄,畢竟都多浪費了一個 instance 的錢了(因為被 ban 掉就不能再用那個 instance 來抓,所以我們就又要多開一個 instance 才會有新的 ip 才可以再繼續抓),所以我們做了第三次的嘗試:
第三版的架構如下
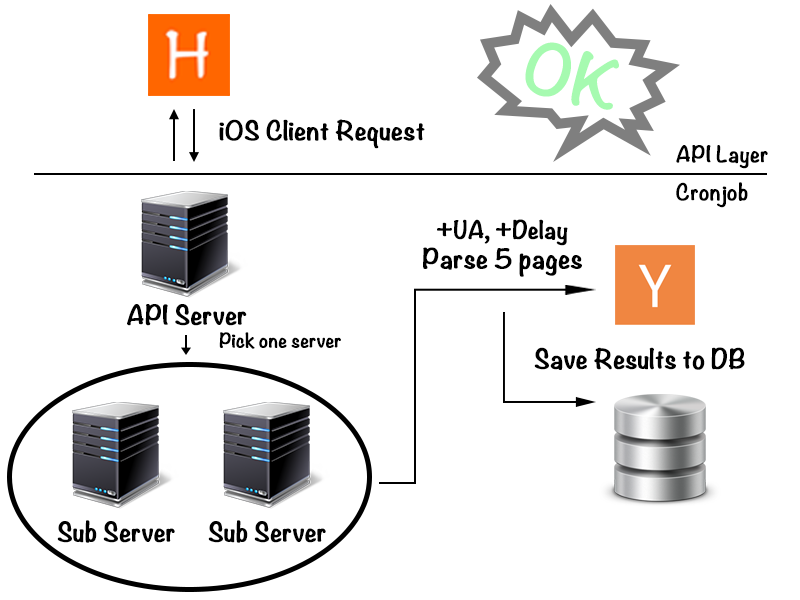
終於成功了!這一次我們改用 Master / Slave 的方法實作,因為原本的 API Server 已經被 Cloud Flare Ban 掉了,所以不能再拿來抓資料了,我們就把它改寫成 Master Server,然後再多買兩個 instance 當成 Slave Server(先前那一個已經關掉了,又再多開兩個全新的,都是錢呀 …),在 Master 的 Cronjob 中會每一個小時依照目前 hh % 2 的數字來決定要呼叫哪個 Slave Server 去做 Fetch + Parse 的動作,然後再存進去資料庫中。
在這個架構下,因為我們多新增了一個 Server 所以分散了流量,對 Hacker News 來說每兩個小時才會被同一台機器爬一次資料,所以在我們的假設(也驗証了)下,Shield 就不再把我們試為惡意的 Bot 了!而經過測試,自從上架後我們目前資料庫的資料也都成功的每一個小時會更新一次,雖沒有太即時但卻完美的解決了我們最初的問題!真的是太令人開心了!
感想
事情沒有絕對,當卡住的時候冷靜下來轉個彎說不定就會有新的想法了。也沒有什麼做不到的事情,只要這件事情是你想做的,每天只要花一兩個小時慢慢做,幾個月後就會慢慢成形了!
寫這麼一大篇是想讓大家知道,一個看似簡單的程式(app)背後可能有多到一般人看不到的問題等待解決,真心希望未來有人想說「為什麼這麼簡單的東西你都要搞這麼久才搞的出來!」這句不理性的話之前,能試著從工程師的角度去看待問題。
「魔鬼都藏在細節裡,而通常,這些細節都要等你做了之後才會發現。」共勉之 😉
雜語(明明就是工商時間 xD)
如果你覺得這篇文章有幫助到你,希望你能透過 app store 下載 支持我們或是來看看我們的 app 介紹頁面,雖然我們目前的 Design 還有其他功能有待加強,但是我們會持續改進這這個 app 做的更好的,如果你有什麼想法也很歡迎寄信給我們哦!
除了這篇文章之外,我接下來會再寫一篇有關 app 介紹頁面及設計的故事,敬請期待 😛